1촌이 아닌 2촌 유저들을 식별하는 방법
Overview.
그래프 데이터베이스는 복잡한 관계와 네트워크를 효과적으로 모델링하고 탐색하기 위해 설계된 데이터베이스 시스템입니다.
특히 관계가 데이터의 중심적인 측면을 차지하는 경우에 유용합니다. 그래프 데이터베이스의 주요 용도는 다음과 같습니다:
- 소셜 네트워킹: 소셜 네트워크는 사람들 사이의 관계를 그래프로 표현하는 데 이상적입니다. 사용자, 친구 관계, 그룹 멤버십 등을 노드와 에지로 모델링할 수 있으며 이를 통해 소셜 네트워크 분석이나 추천 시스템 등을 구현할 수 있습니다.
- 추천 시스템: 제품, 사용자, 구매 기록 등을 그래프 데이터베이스에 저장하여 복잡한 사용자와 제품 간의 관계를 분석하고 개인화된 추천을 제공할 수 있습니다.
위 문제는 관계형 데이터베이스로도 충분히 해결할 수 있습니다. 다만 그래프 데이터베이스를 이용한다면 더욱 복잡한 쿼리를 더 좋은 퍼포먼스로 해결할 수 있습니다.
만약 "David"의 부모의 부모의 부모의 자식의 자식의 자식은 누구고, 몇명인지 알아내려면 어떻게 해야할까요? 혹은 SNS 서비스에서 1촌은 아닌 2촌은 어떻게 구할 수 있을까요?
David 친척을 구하는 쿼리를 SQL로는 다음과 비슷하게 구현해야 할 겁니다.
WITH RECURSIVE Ancestors AS (
SELECT parent_id AS ancestor
FROM ParentChild
WHERE child_id = (
SELECT id
FROM Person
WHERE name = 'David'
)
UNION ALL
SELECT pc.parent_id
FROM ParentChild pc
INNER JOIN Ancestors a ON pc.child_id = a.ancestor
),
Descendants AS (
SELECT child_id AS descendant
FROM ParentChild
WHERE parent_id IN (SELECT ancestor FROM Ancestors)
UNION ALL
SELECT pc.child_id
FROM ParentChild pc
INNER JOIN Descendants d ON pc.parent_id = d.descendant
)
SELECT DISTINCT p.name
FROM Descendants d
JOIN Person p ON d.descendant = p.id;반면에 그래프 데이터베이스에서의 쿼리문은 다음과 같습니다.
graph
.v("David")
.out("parent").out("parent").out("parent")
.in("parent").in("parent").in("parent")
.unique()
.run()그래프 데이터베이스의 쿼리문이 훨씬 읽기에 직관적이지 않나요? 메모리, 성능적으로도 더 유리할 수 있습니다. 이어서 1촌이 아닌 2촌의 유저를 구하는 방법도 다음과 같을겁니다.
graph
.v(1).out("friend").aggregate("firstDegree") // 1촌 친구로 마킹
.out("friend").except("firstDegree") // 1촌 제외
.unique()
.property("name")
.run()그렇다면 그래프 데이터베이스는 어떤 원리를 토대로 구현할 수 있을까요? 그 원리를 살펴보도록 하겠습니다.
Build Graph
먼저 데이터베이스의 쿼리문을 해석할 Query 클래스를 만들기 이전에 기본적인 Graph를 구성하는 클래스를 만들어보도록 하겠습니다.
type VertexId = number | string
interface Vertex {
_id: VertexId
name: string
_in: Edge[]
_out: Edge[]
}
interface Edge {
_in: Vertex
_out: Vertex
_label?: string
}
type PartialVertex = {
_id?: VertexId
name: string
}
type PartialEdge = {
_in: VertexId
_out: VertexId
_label?: string
}
class Graph {
vertices: Vertex[] = []
edges: Edge[] = []
private vertexIndex: Record<VertexId, Vertex> = {}
private autoid: number = 1
constructor(V: PartialVertex[], E: PartialEdge[]) {
this.addVertices(V)
this.addEdges(E)
}
}단순히 vertices와 edges로 이루어진 단방향 그래프입니다. 만약 vertex 생성 시 _id 값이 주어지지 않았다면 autoid를 통해 자동으로 기입됩니다.
class Graph {
private createVertex({ _id, name, ...rest }: PartialVertex): Vertex {
if (!_id) _id = this.autoid++
return {
_id,
name,
...rest,
_in: [],
_out: [],
}
}
public addVertex(partialVertex: PartialVertex): VertexId {
const vertex = this.createVertex(partialVertex)
const existingVertex = this.findVertexById(vertex._id)
if (existingVertex)
throw new Error("A vertex with id " + vertex._id + " already exists")
this.vertices.push(vertex)
this.vertexIndex[vertex._id] = vertex
return vertex._id
}
public addEdge(partialEdge: PartialEdge): void {
const inVertex = this.findVertexById(partialEdge._in)
const outVertex = this.findVertexById(partialEdge._out)
if (!inVertex || !outVertex)
throw new Error("One of the vertices for the edge wasn't found")
const edge: Edge = {
_in: inVertex,
_out: outVertex,
_label: partialEdge._label,
}
outVertex._out.push(edge)
inVertex._in.push(edge)
this.edges.push(edge)
}
private addVertices(vertices: PartialVertex[]): void {
vertices.forEach(vertex => this.addVertex(vertex))
}
private addEdges(edges: PartialEdge[]): void {
edges.forEach(vertex => this.addEdge(vertex))
}
private findVertexById(vertex_id: VertexId): Vertex {
return this.vertexIndex[vertex_id]
}
}실제로 각 vertex와 edge를 만들어내는 코드입니다. 오늘의 Query하는 것이 주제이므로 간단히 살펴보고 넘어갑니다.
Query
이제 데이터가 담긴 그래프에서 Query를 하는 부분을 알아보겠습니다.
type GremlinState = Record<string, any>
interface Gremlin {
vertex: Vertex
state: GremlinState
}
interface State {
vertices?: Vertex[]
edges?: Edge[]
gremlin?: Gremlin
}
type Step = [string, any[]] // [pipetype, args]
class Query {
graph: Graph
state: State[]
program: Step[]
gremlins: Gremlin[]
constructor(graph: Graph) {
this.graph = graph
this.state = []
this.program = []
this.gremlins = []
}
}쿼리의 기본적인 구조는 위와 같이 생겼습니다. 꽤 낯섭니다. 하나씩 알아보도록 하겠습니다.
program은 각 쿼리의 단계를 저장하고 있는 변수입니다. 각 스텝은 추후에 설명할 파이프로 이루어져있습니다.
각 스텝은 상태를 가질 수 있고 query의 state에 각 스텝 단계 인덱스에 대응하는 상태를 저장합니다.
그렘린은 우리의 명령에 따라 그래프를 통해 이동하는 생물입니다. 그렘린은 자신이 어디에 있었는지 기억하고 우리가 query하는 답을 찾을 수 있도록 도와줍니다. (그래프 DB에서 그렘린이라는 생물의 기원은 https://docs.janusgraph.org/getting-started/gremlin/ 그렘린 언어로 거슬러 올라갑니다.)
이전에 우리가 David의 친척을 찾기위해 작성했던 그래프언어가 그렘린 쿼리 언어입니다.
graph
.v("David")
.out("parent").out("parent").out("parent")
.in("parent").in("parent").in("parent")각 파이프라인(스텝)에 해당하는 함수를 파이프라고 하며 위의 예문에서는 v, out, in 의 파이프가 사용되었습니다. 각 스텝의 파이프를 저장하기 위해 Query 클래스에 프로그램에 파이프를 추가하는 add 함수를 만들고 Graph에서 쿼리할 수 있는 v 함수를 만듭니다.
class Graph {
...
public v(...args: any[]) {
const query = new Query(this)
query.add('vertex', args)
return query
}
}
class Query {
...
add(pipetype: string, args: any[]) {
const step: Step = [pipetype, args]
this.program.push(step)
return this
}
}여기서 pipetype은 무엇을 뜻하는 걸까요? 그 답은 다음 절에서 알아보겠습니다.
Eager Loading Problem
pipetype에 대해 살펴보기 이전에 현재 작성하는 쿼리문을 실행하는 전략에 대해 살펴볼 필요가 있습니다.
첫번째는 파이프라인을 확인하는 즉시 실행하는 전략이 있고, 두번째는 정말로 필요하기 전까지 실행하지 않는 전략이 있습니다. 첫번째를 eager loading이라 하고, 두번째를 lazy loading이라고 하겠습니다.
만약 eager loading 전략으로 쿼리를 실행하는 경우, 우리가 david의 친척을 찾을 때 성능상의 문제가 발생할 수 있습니다. 실제로 우리가 원하는 친척 대상의 결과가 수만명이라 할지라도, 진정 원하는 결과는 아닐 겁니다. 서비스에서 보여줄 때는 .take(20)과 같이 보여줄만큼의 필터링을 통해 노드를 제한합니다. 쿼리문은 다음과 같습니다.
graph
.v("David")
.out("parent").out("parent").out("parent")
.in("parent").in("parent").in("parent")
.take(20).take가 가장 뒷 부분에 있기 때문에 이는 문제가 발생할 수 있습니다. 반면에 lazy loading으로 처리한다면 마지막에 20개의 결과만 내보내면 되기 때문에 불필요한 리소스 낭비를 방지할 수 있습니다. 그래프 데이터베이스에서 우리는 lazy loading 방식으로 실행을 처리하는 것이 현명할 겁니다.
이제 vertex, in, out, take 등 다양한 pipetype의 구현을 만들어 실제 쿼리를 할 때 이용할 수 있도록 합니다. 그 전에 한가지 살펴보아야할 것이 있는데, 바로 각 파이프라인의 lazy loading의 구현입니다.
Query run: interpreter
이전에 논의한 것처럼 우리는 lazy loading에 기반한 쿼리 실행 전략을 구성하려 합니다. 그러려면 우선 쿼리문의 메소드 체이닝을 끝가지 읽으면서 pipetype을 모두 저장하고 있어야 하고, 실행 계획에 따라 다시 거슬러 올라갈 수도 있어야한다는 겁니다. run 함수에 대해 부분적으로 작성해보면 다음과 같습니다.
class Query {
graph: Graph
state: State[]
program: Step[]
gremlins: Gremlin[]
constructor(graph: Graph) {
this.graph = graph
this.state = []
this.program = []
this.gremlins = []
}
run() {
const max = this.program.length - 1
let currentResult: MaybeGremlin = false
const results = []
let done = -1
let pc = max
while (done < max) {
const [operationType, parameters] = this.program[pc]
const state = (this.state[pc] = this.state[pc] || {})
const operate = Dagoba.getPipetype(operationType)
currentResult = operate(this.graph, parameters, currentResult,
state, pc - 1 <= done)변수설명
- graph: 그래프 데이터베이스의 구조입니다.
- state: 각 단계별로 현재 상태 정보를 저장하는 배열입니다.
- program: 실행할 연산의 시퀀스를 담고 있는 배열입니다. 예를 들어 쿼리문
graph.v(1).out('knows').out().take(2)이 존재한다고 하면,program은[['v', [1]], ['out', ['knows']], ['out', []], ['take', [2]]]와 같이 될겁니다. - max: 실행할 마지막 연산의 인덱스입니다.
- currentResult: 현재 연산의 결과를 저장하는 임시 변수입니다.
- results: 최종 결과를 저장하는 배열입니다.
- done: 마지막으로 완료된 연산의 인덱스입니다.
- pc: 프로그램 카운터, 현재 실행 중인 연산의 인덱스입니다.
실행과정
- 초기화:
pc는 마지막 연산 인덱스(max)로 초기화됩니다.done은 -1로 설정되어 초기에는 모든 연산이 완료되지 않았음을 나타냅니다. - 메인 루프:
done이max보다 작은 동안 루프를 실행합니다. 이는 모든 연산이 완료될 때까지 계속됩니다. - 연산 실행:
program[pc]에서 연산 유형과 매개변수를 추출하고, 해당 연산 유형에 맞는 함수(Dagoba.getPipetype(operationType))를 호출하여 실행합니다. 연산의 결과는currentResult에 저장됩니다.
그 다음 로직은 다음과 같습니다.
if (currentResult == 'pull') {
currentResult = false
if (pc - 1 > done) {
pc--
continue
} else {
done = pc
}
}
if (currentResult == 'done') {
currentResult = false
done = pc
}
pc++
if (pc > max) {
if (currentResult) results.push(currentResult)
currentResult = false
pc--
}
}
return results.map((gremlin) => (gremlin.result != null ? gremlin.result : gremlin.vertex))
}
}-
결과 처리:
- 'pull' 결과: 현재 연산이 더 많은 입력을 요구하는 경우(
pull),currentResult를false로 설정하고, 이전 단계(pc - 1)로 돌아가 연산을 계속합니다. - 'done' 결과: 현재 연산이 완료된 경우(
done),currentResult를false로 설정하고,done을 현재의pc값으로 업데이트합니다.
- 'pull' 결과: 현재 연산이 더 많은 입력을 요구하는 경우(
-
인덱스 조정:
pc값을 증가시켜 다음 연산으로 이동합니다.pc가max보다 크면, 현재 결과(currentResult)가 유효하다면 결과 배열에 추가하고,currentResult를false로 설정한 후pc를 감소시켜 이전 단계로 돌아갑니다. -
결과 반환: 최종 결과 배열을 매핑하여 각 Gremlin의 결과를 추출하고 반환합니다. 결과가 없는 경우(
null)는 해당 Gremlin의 정점(vertex)을 반환합니다.
즉 각 pipetype의 결과에 따라 pc는 좌 혹은 우로 지속적으로 왔다갔다 할 수 있습니다. pc가 우 방향으로 갈 때 이전에 수행했던 결과를 currentResult에 gremlin으로서(혹은 false 등) 저장합니다.
done의 역할
done이 되는 상황은 특정 연산이 완료되어 더 이상 진행할 필요가 없을 때 발생합니다. 코드에서 done의 역할과 설정 시점을 자세히 살펴보면 다음과 같은 두 가지 주요 상황에서 done이 업데이트됩니다:
-
Pull이 반환될 때. 그리고 이전 단계로 돌아갈 수 없을 때:
currentResult가 'pull'을 반환하면 이는 현재 연산이 추가 데이터나 입력을 필요로 하고 있음을 의미합니다. 이 경우pc(프로그램 카운터)를 감소시켜 이전 단계의 연산을 다시 수행합니다.- 만약
pc - 1이done보다 작거나 같다면 (if (pc - 1 <= done)) 모든 이전 단계의 연산들이 이미 완료된 것으로 간주되므로 더 이상 돌아갈 이전 단계가 없습니다. 이 때done을 현재의pc값으로 설정하여 현재 연산까지 완료된 것으로 표시합니다.
-
연산이 'done'을 반환할 때:
- 연산 함수에서 'done' 결과가 반환되면 이는 해당 연산이 완전히 완료되었음을 의미합니다. 따라서
currentResult를false로 설정하고done을 현재의pc값으로 업데이트합니다. 이렇게 하여 해당 연산이 완료되었고 더 이상 실행할 필요가 없음을 나타냅니다.
- 연산 함수에서 'done' 결과가 반환되면 이는 해당 연산이 완전히 완료되었음을 의미합니다. 따라서
이 두 상황은 연산이 더 이상 진행되지 않고 중단되어야 하는 지점을 나타내며 이는 쿼리 실행 프로세스에서 중요한 체크 포인트입니다.
결과적으로 run 함수를 수행하여 results 변수에 우리가 원하는 결과 노드가 담겨 반환됩니다.
Pipetypes
Pipetypes는 dagoba 시스템의 핵심입니다. 각각의 작동방식을 이해하면 인터프리터에서 이들이 어떻게 호출되고 순서가 지정되는지 더 잘 이해할 수 있습니다.
class Dagoba {
static Pipetypes: Record<string, Function> = {}
static addPipetype(name: string, fun: Function) {
Dagoba.Pipetypes[name] = fun
Query.prototype[name] = function () {
return this.add(name, [].slice.apply(arguments))
}
}
static getPipetype(name: string) {
return Dagoba.Pipetypes[name]
}
}addPipetype 함수 호출을 통해 쿼리에서 호출할 수 있는 파이프 유형이 추가됩니다. 그리고 Query 클래스 내부에서 각 파이프라인을 평가할 때 getPipetype 함수 호출을 통해 pipetype 함수를 가져옵니다.
pipetype: vertex
vertex pipetype은 해당 노드의 그렘린을 생성하는 역할을 합니다. 조건에 맞는 모든 정점을 가져와 한 번에 하나씩 그렘린을 생성합니다.
Dagoba.addPipetype("vertex", function (graph, args, gremlin, state) {
if (!state.vertices) state.vertices = graph.findVertices(args) // state initialization
if (!state.vertices.length)
// all done
return "done"
const vertex = state.vertices.pop() // OPT: this relies on cloning the vertices
return Dagoba.makeGremlin(vertex, gremlin.state) // we can have incoming gremlins from as/back queries
})pipetype: in-out
그래프 노드에서 연결되어있는 간선을 따라 다음 노드를 탐색하는 것은 무척 쉽습니다.
Dagoba.addPipetype("in", simpleTraversal("in"))
Dagoba.addPipetype("out", simpleTraversal("out"))simpleTraversal 함수는 'in'과 'out' 방향은 각각 해당 노드로 들어오는 간선과 나가는 간선을 나타냅니다. 이 함수는 그래프 구조에서 다음 노드를 순회하는 과정을 담당합니다.
const simpleTraversal = function (dir) {
// handles basic in and out pipetypes
const find_method = dir == "out" ? "findOutEdges" : ("findInEdges" as const)
const edge_list = dir == "out" ? "_in" : ("_out" as const)
return function (graph, args, gremlin, state) {
if (!gremlin && (!state.edges || !state.edges.length))
// query initialization
return "pull"
if (!state.edges || !state.edges.length) {
// state initialization
state.gremlin = gremlin
state.edges = graph[find_method](gremlin.vertex) // get edges that match our query
.filter(Dagoba.filterEdges(args[0]))
}
if (!state.edges.length)
// all done
return "pull"
const vertex = state.edges.pop()[edge_list] // use up an edge
return Dagoba.gotoVertex(state.gremlin, vertex)
}
}함수의 실행 과정에서는 먼저 쿼리 및 상태 초기화 단계가 있습니다. 만약 Gremlin 객체가 존재하지 않거나 처리할 간선이 더 이상 없다면 'pull'을 반환하여 추가 정보를 요청합니다. 만약 Gremlin이 존재하지만 아직 초기 상태가 설정되지 않았다면 현재 정점에서 적절한 방향의 간선을 찾아 상태 정보에 추가합니다.
다음으로 간선 처리 과정이 진행됩니다. 만약 처리할 간선이 남아있지 않으면 다시 'pull'을 반환하여 순회를 중단합니다. 처리할 간선이 남아 있다면 해당 간선을 사용하여 다음 정점으로 이동하고 새로운 Gremlin 객체를 생성하여 반환하여 다음 파이프타입에서 처리할 수 있도록 합니다.
pipetype: property
property 파이프타입은 노드의 특정 속성 값을 추출하는 역할을 합니다.
Dagoba.addPipetype("property", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
gremlin.result = gremlin.vertex[args[0]]
return gremlin.result == null ? false : gremlin // undefined or null properties kill the gremlin
})함수의 실행 과정은 먼저 쿼리 초기화 단계를 포함합니다. 이 단계에서 Gremlin 객체가 존재하지 않을 경우 함수는 'pull'을 반환합니다.
Gremlin 객체의 현재 노드에서 원하는 속성을 추출하여 결과로 설정합니다. 이때 설정된 속성 값이 null이나 undefined일 경우, 함수는 false를 반환하며 이는 Gremlin의 순회를 종료시킵니다.
pipetype: unique
unique 파이프타입은 중복된 노드의 방문을 방지하여 데이터 처리의 효율성을 높이고 순회 과정에서 불필요한 반복을 제거합니다.
Dagoba.addPipetype("unique", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
if (state[gremlin.vertex._id]) return "pull" // we've seen this gremlin, so get another instead
state[gremlin.vertex._id] = true
return gremlin
})먼저 함수는 Gremlin 객체의 존재 여부를 확인합니다. Gremlin 객체가 없다면, 'pull'을 반환하여 쿼리 초기화 단계에서 추가적인 데이터를 요청합니다.
다음으로 함수는 현재 Gremlin이 방문한 노드가 이미 방문되었는지를 검사합니다. 이를 위해 상태 객체 state를 사용하여 각 노드의 고유 ID를 키로 하여 방문 여부를 저장합니다. 만약 현재 노드가 이미 방문된 경우에는 'pull'을 반환하여 다른 Gremlin을 요청합니다.
만약 현재 노드가 이전에 방문되지 않았다면 해당 노드의 ID를 상태 객체에 저장하고 Gremlin 객체를 그대로 반환합니다. 이렇게 함으로써 함수는 각 노드를 단 한 번만 순회하게 합니다.
pipetype: filter
filter 파이프타입은 다양한 방식으로 필터링 조건을 지정할 수 있으며 해당 조건을 만족하는 노드에 대해서만 순회를 계속하게 합니다.
Dagoba.addPipetype("filter", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
if (typeof args[0] == "object")
// filter by object
return Dagoba.objectFilter(gremlin.vertex, args[0]) ? gremlin : "pull"
if (typeof args[0] != "function") {
Dagoba.error("Filter arg is not a function: " + args[0])
return gremlin // keep things moving
}
if (!args[0](gremlin.vertex, gremlin)) return "pull" // gremlin fails filter function
return gremlin
})다른 pipetype 함수와 마찬가지로 Gremlin이 없으면 'pull'을 반환합니다. 이후에 인자의 타입(객체 또는 함수)에 따라 필터링이 되고, 통과되었다면 다음 순회를 위해 Gremlin을 그대로 반환합니다.
pipetype: take
take 파이프타입은 그래프 데이터베이스에서 순회 중인 노드들 중에서 지정된 수의 노드만 선택하고 그 이후의 순회를 중단하는 기능을 수행합니다.
Dagoba.addPipetype("take", function (graph, args, gremlin, state) {
state.taken = state.taken || 0 // state initialization
if (state.taken == args[0]) {
state.taken = 0
return "done" // all done
}
if (!gremlin) return "pull" // query initialization
state.taken++ // THINK: if this didn't mutate state, we could be more
return gremlin // cavalier about state management (but run the GC hotter)
})함수는 먼저 상태 객체 state의 초기화를 확인합니다. 여기서 state.taken은 현재까지 취한 노드의 수를 저장하는 변수로 초기에는 0으로 설정됩니다.
순회 과정에서 먼저 지정된 개수(args[0])만큼 노드를 처리했는지 확인합니다. 만약 지정된 개수만큼 노드를 이미 처리했다면 state.taken을 0으로 재설정하고 'done'을 반환하여 순회를 종료합니다.
그리고 Gremlin 객체의 존재 여부를 검사합니다. Gremlin 객체가 없으면 'pull'을 반환하여 추가 데이터를 요청하고 쿼리 초기화를 진행합니다.
만약 Gremlin 객체가 존재하면 state.taken 값을 1 증가시켜 현재까지 처리한 노드의 수를 업데이트합니다. 이후에는 현재의 Gremlin 객체를 반환하여 순회를 계속합니다.
pipetype: as
as 파이프타입은 그래프 데이터베이스에서 순회 중인 노드를 특정 레이블로 태그하는 기능을 제공합니다. 이를 통해 나중에 특정 지점을 참조하거나 다시 방문할 수 있게 됩니다.
Dagoba.addPipetype("as", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
gremlin.state.as = gremlin.state.as || {} // initialize gremlin's 'as' state
gremlin.state.as[args[0]] = gremlin.vertex // set label to the current vertex
return gremlin
})처음으로 함수는 Gremlin 객체의 존재 여부를 검사합니다. Gremlin 객체가 없는 경우 'pull'을 반환하여 쿼리 초기화 단계에서 필요한 추가 데이터를 요청합니다.
이어서 Gremlin 객체의 'as' 상태를 초기화합니다. 여기서 gremlin.state.as는 현재까지 태그된 노드들을 저장하는 객체입니다. 만약 이 상태가 아직 설정되지 않았다면 새로운 객체로 초기화됩니다.
함수는 현재 순회 중인 노드(gremlin.vertex)를 특정 레이블(args[0])에 할당합니다. 이 레이블은 사용자가 함수를 호출할 때 지정한 인자입니다.
pipetype: except
except 파이프타입은 그래프 데이터베이스의 순회 과정에서 특정 노드를 제외합니다.
Dagoba.addPipetype("except", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
if (
gremlin.state.as &&
gremlin.state.as[args[0]] &&
gremlin.vertex == gremlin.state.as[args[0]]
)
return "pull" // TODO: check for nulls
return gremlin
})함수는 Gremlin 객체의 존재 여부를 확인합니다. 만약 Gremlin 객체가 존재하지 않는 경우 'pull'을 반환하여 추가적인 데이터 요청과 함께 쿼리 초기화 단계를 진행합니다.
먼저 gremlin.state.as 객체 내에 저장된 특정 레이블의 노드와 현재 순회 중인 노드가 같은지 확인합니다. 이 레이블은 함수 호출 시 제공된 인자(args[0])에 의해 지정됩니다. 만약 현재 노드가 이 레이블로 태그된 노드와 동일하다면 'pull'을 반환하여 해당 노드를 순회 결과에서 제외합니다.
pipetype: back
back 파이프타입은 그래프 데이터베이스의 순회 과정에서 특정 레이블로 태그된 노드로 돌아가는 기능을 제공합니다.
Dagoba.addPipetype("back", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
return Dagoba.gotoVertex(gremlin, gremlin.state.as[args[0]]) // TODO: check for nulls
})먼저 Gremlin 객체의 state 내부에 저장된 as 객체를 참조합니다. 이 객체 내부에는 레이블과 해당 레이블에 할당된 노드의 참조가 저장되어 있습니다. 함수는 이 정보를 사용하여 호출 시 제공된 인자로 지정된 레이블의 노드로 돌아갑니다.
만약 지정된 레이블에 해당하는 노드가 존재한다면, Dagoba.gotoVertex 함수를 사용하여 해당 노드로 Gremlin의 위치를 이동시킵니다.
Examples
위에서 구현한 query와 pipetype들을 통하여 여러 예제를 만들어볼 수 있습니다.
지인관계
class DagobaTest1 {
static run() {
const V = [
{ name: "alice" }, // alice gets auto-_id (prolly 1)
{ _id: 10, name: "bob", hobbies: ["asdf", { x: 3 }] },
]
const E = [{ _out: 1, _in: 10, _label: "knows" }]
const graph = Dagoba.graph(V, E)
graph.addVertex({ name: "charlie", _id: "charlie" })
graph.addVertex({ name: "delta", _id: "30" })
graph.addEdge({ _out: 10, _in: 30, _label: "parent" })
graph.addEdge({ _out: 10, _in: "charlie", _label: "knows" })
// @ts-ignore
const result1 = graph.v(1).out("knows").out().run()
console.log(result1)
// @ts-ignore
const qb = graph.v(1).out("knows").out().take(1).property("name")
const result2 = qb.run()
const result3 = qb.run()
const result4 = qb.run()
console.log(result2, result3, result4)
}
}
DogobaTest1.run()그래프를 구성해보면 다음과 같습니다.
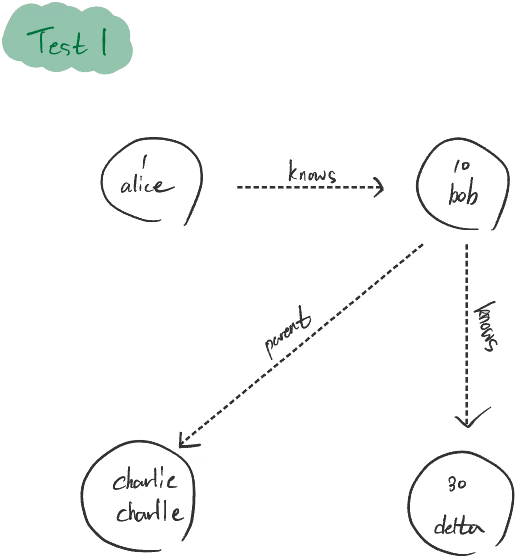
첫 번째 쿼리 실행 (result1):
graph.v(1).out('knows').out().run(): ID가 1인 노드(Alice)에서 시작하여 'knows' 관계를 통해 연결된 노드(Bob)로 이동한 다음 Bob과 관련된 노드를 탐색합니다. Bob은 Delta와 Charlie 두 노드와 관계가 있으므로 이 노드들이 결과로 반환됩니다.
두 번째 쿼리 시리즈 (result2, result3, result4):
graph.v(1).out('knows').out().take(1).property('name'): 이 쿼리 체인은 Alice에서 시작하여 Bob을 거쳐 그와 연결된 노드들 중 하나를 선택(take(1))하고, 선택된 노드의 이름 속성을 추출합니다. take(1)이 적용되므로 첫 번째 실행에서는 Bob과 관계된 첫 번째 노드(Delta 또는 Charlie 중 하나)의 이름이 결과로 반환됩니다. 두 번째 run()에서는 두 번째 노드의 이름이 반환되고, 세 번째에서는 더 이상 반환할 노드가 없으므로 빈 배열을 반환합니다.
result1: [
{ _id: "charlie", name: "charlie", _in: [[Object]], _out: [] },
{ _id: "30", name: "delta", _in: [[Object]], _out: [] },
]
result2: ["charlie"]
result3: ["delta"]
result4: []과목 수강
class DagobaTest2 {
static run() {
const V = [
{ name: "Alice", _id: 1, type: "student" },
{ name: "Bob", _id: 2, type: "student" },
{ name: "Charlie", _id: 3, type: "student" },
{ name: "Mathematics", _id: 4, type: "course" },
{ name: "Computer Science", _id: 5, type: "course" },
]
const E = [
{ _out: 1, _in: 4, _label: "enrolled" },
{ _out: 1, _in: 5, _label: "enrolled" },
{ _out: 2, _in: 4, _label: "enrolled" },
{ _out: 3, _in: 5, _label: "enrolled" },
]
const graph = Dagoba.graph(V, E)
const dualEnrolledStudents = graph
.v()
// @ts-ignore
.filter({ type: "student" })
.as("student")
.out("enrolled")
.filter({ name: "Mathematics" })
.back("student")
.out("enrolled")
.filter({ name: "Computer Science" })
.back("student")
.unique()
.property("name")
.run()
console.log(
"Students enrolled in both Mathematics and Computer Science:",
dualEnrolledStudents
)
}
}
DogobaTest2.run()그래프를 구성해보면 다음과 같습니다.
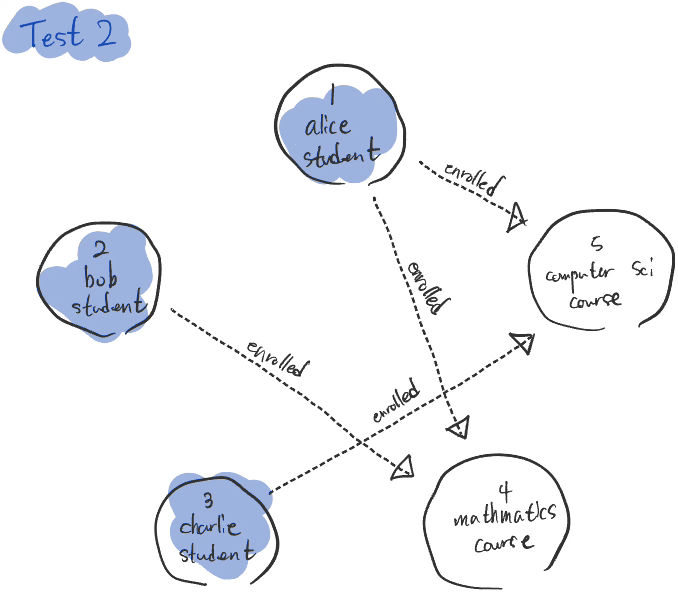
쿼리의 내용은 즉 수학과 컴퓨터 과목 두 가지를 모두 수강하는 학생을 구하는 겁니다. 조금 복잡해보일 수 있으나 차례대로 해석해보겠습니다.
- 학생 필터링: 모든 Vertex 중
type이 'student'인 것들만 선택합니다. - 학생 태그 설정: 각 학생 Vertex에 'student'라는 태그를 설정합니다.
- Mathematics 과목 필터링: 각 학생이 등록된 과목 중 "Mathematics"에 등록된 과목을 필터링합니다.
- 원 학생 Vertex로 돌아가기: 'student' 태그를 통해 원래의 학생 Vertex로 돌아갑니다. 만약 수학 과목 필터링에서 과목이 없어서 그렘린이 존재하지 않았다면 원 학생으로 돌아가지 않고 'pull'을 반환합니다.
- Computer Science 과목 필터링: 동일한 학생이 "Computer Science"에 등록된 과목을 다시 필터링합니다. 마찬가지로 컴퓨터 과목 필터링에서 과목이 없어서 그렘린이 존재하지 않았다면 원 학생으로 돌아가지 않고 'pull'을 반환합니다.
- 중복 제거: 여기까지 왔다는 건 두 과목을 모두 수강하는 학생이었다는 겁니다. 동일한 학생 정보가 중복되지 않도록
unique함수를 사용하여 중복을 제거합니다. - 학생 이름 추출: 최종적으로 선택된 학생의 'name' 속성을 추출합니다.
Students enrolled in both Mathematics and Computer Science: [ 'Alice' ]1촌이 아닌 2촌
class DagobaTest3 {
static run() {
const V = [
{ _id: 1, name: "User1" },
{ _id: 2, name: "User2" },
{ _id: 3, name: "User3" },
{ _id: 4, name: "User4" },
{ _id: 5, name: "User5" },
{ _id: 6, name: "User6" },
{ _id: 7, name: "User7" },
{ _id: 8, name: "User8" },
{ _id: 9, name: "User9" },
{ _id: 10, name: "User10" },
]
const E = [
{ _out: 1, _in: 2, _label: "friend" },
{ _out: 1, _in: 3, _label: "friend" },
{ _out: 1, _in: 4, _label: "friend" },
{ _out: 1, _in: 9, _label: "friend" },
{ _out: 1, _in: 10, _label: "friend" },
{ _out: 2, _in: 5, _label: "friend" },
{ _out: 2, _in: 6, _label: "friend" },
{ _out: 3, _in: 7, _label: "friend" },
{ _out: 3, _in: 8, _label: "friend" },
{ _out: 4, _in: 9, _label: "friend" },
{ _out: 4, _in: 10, _label: "friend" },
{ _out: 5, _in: 10, _label: "friend" },
{ _out: 6, _in: 10, _label: "friend" },
{ _out: 7, _in: 1, _label: "friend" },
{ _out: 8, _in: 9, _label: "friend" },
{ _out: 9, _in: 2, _label: "friend" },
{ _out: 9, _in: 6, _label: "friend" },
{ _out: 10, _in: 3, _label: "friend" },
]
const graph = Dagoba.graph(V, E)
const secondDegreeFriendsOfUser3 = graph
.v(1) // 1번 유저 시작
// @ts-ignore
.out("friend") // 1촌 친구
.aggregate("firstDegree") // 1촌 친구로 마킹
.out("friend") // 2촌 친구
.except("firstDegree") // 1촌 제외
.unique() // 중복 제거
.property("name") // 이름 추출
.run() // 쿼리 실행
console.log("2nd degree friends of User 1:", secondDegreeFriendsOfUser3)
}
}
DogobaTest3.run()그래프를 구성해보면 다음과 같습니다.
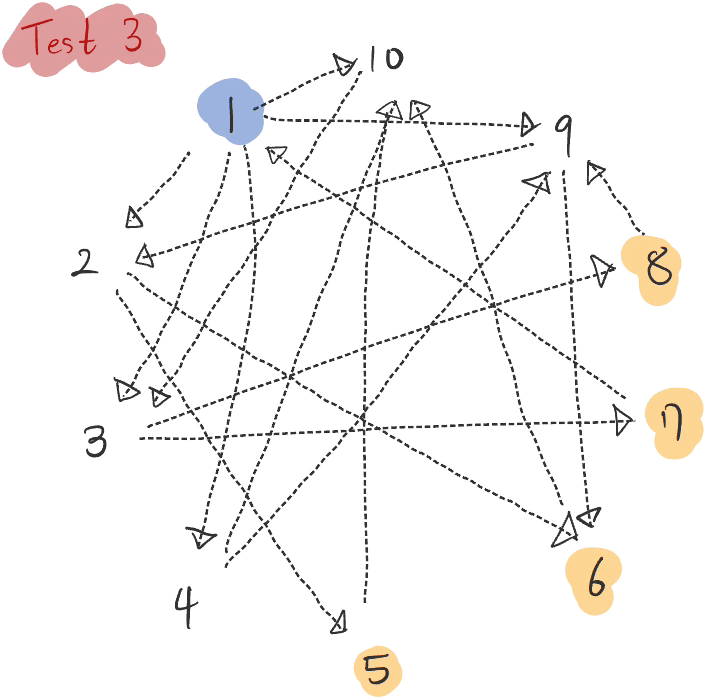
이 아티클 처음 부분에 언급했던 쿼리 내용입니다. 쿼리 내용 자체는 간단합니다.
const secondDegreeFriendsOfUser3 = graph
.v(1) // 1번 유저 시작
// @ts-ignore
.out("friend") // 1촌 친구
.aggregate("firstDegree") // 1촌 친구로 마킹
.out("friend") // 2촌 친구
.except("firstDegree") // 1촌 제외
.unique() // 중복 제거
.property("name") // 이름 추출
.run() // 쿼리 실행d다만 여기에서는 우리가 못보던 pipetype 한가지가 존재합니다. aggregate 입니다. 왜 1촌을 as로 지정해서 제외시킬 수 없었던 걸까요?
aggregate 파이프타입을 사용하는 주된 이유는 여러 항목을 모으고 특정 단계에서 이루어진 처리 결과를 중간에 집계하여 나중에 참조할 수 있도록 하기 위함입니다. as 파이프타입과 aggregate 파이프타입은 비슷한 기능을 수행할 수 있지만, 목적과 사용 방식에는 차이가 있습니다.
as는 주로 현재 노드나 경로의 특정 지점을 마킹하여 이후 쿼리 단계에서 "돌아가기(back)" 기능을 수행할 때 사용됩니다. 주로 단일 요소에 대한 참조를 저장하는 데 사용되며 한 번에 하나의 노드만 태그할 수 있습니다. 따라서 다수의 노드를 집계하거나 이후의 쿼리에서 다시 사용하기 위해 여러 노드를 그룹화하는 데는 적합하지 않습니다.
aggregate는 여러 노드를 컬렉션으로 모을 수 있으며 이 컬렉션은 이후 쿼리 단계에서 필터링이나 다른 연산의 대상이 될 수 있습니다. 따라서 aggregate 파이프타입을 추가로 구현하고 except에서 이 aggregate까지 인식할 수 있도록 코드를 조금 수정해보겠습니다.
Dagoba.addPipetype("aggregate", function (graph, args, gremlin, state, done) {
if (!done && !gremlin) return "pull" // query initialization
state.aggregate = state.aggregate || {} // initialize gremlin's 'aggregate' state
if (!state.aggregate[args[0]]) state.aggregate[args[0]] = []
if (done) {
if (!state.aggregated) {
state.aggregated = true
state.vertices = [...state.aggregate[args[0]]]
}
const vertex = state.vertices.pop()
if (!vertex) return "pull"
const gremlin = Dagoba.makeGremlin(vertex, state)
return gremlin
}
state.aggregate[args[0]].push(gremlin.vertex)
gremlin.state.aggregate = gremlin.state.aggregate || {}
gremlin.state.aggregate[args[0]] = state.aggregate[args[0]]
return "pull"
})
Dagoba.addPipetype("except", function (graph, args, gremlin, state) {
if (!gremlin) return "pull" // query initialization
if (
gremlin.state.aggregate[args[0]] &&
gremlin.state.aggregate[args[0]].includes(gremlin.vertex)
)
return "pull"
if (
gremlin.state.as &&
gremlin.state.as[args[0]] &&
gremlin.vertex == gremlin.state.as[args[0]]
)
return "pull" // TODO: check for nulls
return gremlin
})데이터 수집:
- 순회 중인 각 노드는 지정된 집합(
args[0])에 추가됩니다. 이 집합의 이름은 함수가 호출될 때 인자로 제공됩니다. 예를 들어, 사용자가 'firstDegreeFriends'라는 인자를 제공하면, 해당 이름으로 노드들이 집계됩니다.
조건부 처리와 결과 반환:
- 모든 데이터가 수집되면, 즉
done플래그가 참으로 설정되면, 수집된 노드들 중에서 하나씩 노드를 꺼내 Gremlin을 생성하고 반환합니다. 이 과정은 모든 노드가 처리될 때까지 반복됩니다. - 만약 더 이상 반환할 노드가 없다면, 'pull'을 반환하여 순회가 계속될 수 있도록 합니다.
상태 관리
state.aggregated플래그는 수집된 노드들이 이미 처리되었는지를 추적합니다. 이 플래그가 설정되지 않은 경우, 즉 처음으로done조건을 만족했을 때, 수집된 노드들을 배열로 복사하여 순차적으로 처리할 준비를 합니다.- 각 노드가 처리된 후,
state.vertices배열에서 노드를 하나씩 제거하며 해당 노드를 기반으로 새 Gremlin을 생성하여 반환합니다.
결과는 다음과 같습니다.
2nd degree friends of User 1: [ 'User6', 'User5', 'User8', 'User7' ]Summary.
그래프 데이터베이스의 원리에 대해 학습하면서 Lazy loading에 대한 개념과 인터프리터의 가장 일반적인 로직에 대해 조금 더 깊이 들여다볼 수 있었습니다. 또한 관계에 기반한 쿼리를 직관적으로 작성할 수 있는 것에도 매료 되었습니다. aggregate와 같은 pipetype을 새로 고안해보며 그래프 DB 쿼리 원리에 대해 이해할 수 있었습니다. 만약 시간을 더 내어본다면 성능 수준을 지키거나 더 향상시키는 면에서 다양한 pipetype을 작성하여 쿼리를 단축 시키거나 다양화 해볼 수 있을 것 같습니다.
이 케이스 스터디를 진행하며 작성한 코드는 여기에 있습니다.