문자열학의 기초
공단어
문자가 없는 문자열은 라고 하며, 로 나타냅니다.
켤레류
문자열 알고리즘에서 켤레류는 문자열의 회전을 통해 얻을 수 있는 문자열들의 집합입니다.
예를 들어 문자열 "abcde"의 켤레류는 다음과 같은 문자열로 구성됩니다.
- "abcde" (원래 문자열)
- "bcdea" (앞의 문자 'a'를 맨 뒤로 옮김)
- "cdeab" (앞의 두 문자 'ab'를 뒤로 옮김)
- "deabc" (앞의 세 문자 'abc'를 뒤로 옮김)
- "eabcd" (앞의 네 문자 'abcd'를 뒤로 옮김)
켤레류 기호를 라 한다면 다음과 같습니다.
주기성
가 공단어가 아닌 단어라고 가정합니다. 만약 에 대해 이면 인 정수 는 의 라고 합니다.
의 는 로 나타내며 가장 짧은 주기입니다. 예를 들어 3,6,7,8은 의 주기이고, 입니다.
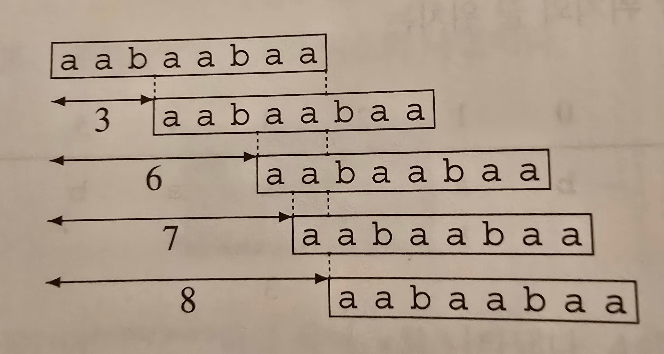
마지막으로 의 개념이 있습니다. 의 경계는 의 접두사이면서 접미사인 의 고유한 인자입니다. 의 는 로 나타내고, 가장 긴 경계입니다. 따라서 는 의 경계이고, 입니다.
원시적
공단어가 아닌 단어 가 어떤 다른 단어의 거듭제곱도 아니라면 그 단어는 라고 합니다.
말하자면, 어떤 단어 와 양수 에 대해 이면 가 원시적이라는 것은 이라는 것을 함의하며, 입니다.
예를 들어 는 원시적이고, 과 은 그렇지 않습니다.
공단어가 아닌 단어는 정확히 하나의 가 있어서, 원시 단어의 거듭제곱이 그 단어가 되는 원시 단어를 가진다는 것이 유도됩니다.
고 가 원시적이면, 는 의 이라고 하고 는 그 지수라고 하며 라고 나타냅니다.
더 일반적으로 의 지수는 인 양이고, 정수일 필요는 없습니다. 만약 그 지수가 최소한 2라면, 그 단어는 이라고 합니다.
단어의 켤레의 수 즉, 켤레류의 크기는 그 원시근의 길이임을 알아둡니다.
원시성 보조정리, 동기화 보조정리
공단어가 아닌 단어 가 원시적이라는 것과, 그 제곱의 인자에 가 접두사와 접미사로만 포함된다는 것은 서로 필요충분조건입니다. 또는 동등하게 인 것과 필요충분조건입니다.
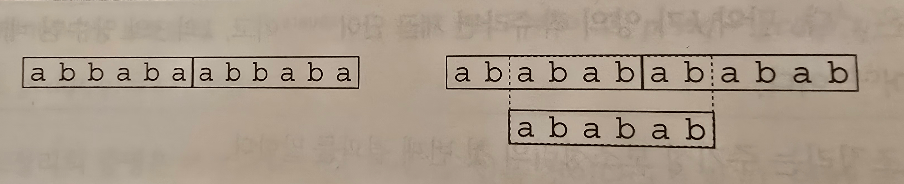
위의 그림은 이 보조정리의 결과를 묘사합니다. 단어 abbaba는 원시적이며, 그 제곱에는 딱 2번만 출현하지만, ababab는 원시적이지 않으며 그 제곱에는 4번 출현합니다.
1. 페르마의 작은 정리의 문자열학적인 증명
문제
만약 가 소수이고 가 임의의 자연수라면, 는 로 나누어 떨어진다.
이 진술은 라고 한다.
예를 들어 는 로 나누어 떨어지고, 은 로 나누어 떨어진다.
질문: 페르마의 작은 정리를 문자열학적인 알고리듬만 사용해 증명하라.
[힌트: 길이가 인 단어의 켤레류를 세어라.]
풀이
이 성질을 증명하기 위해 같은 길이를 갖는 단어의 켤레류를 생각해봅니다. 예를 들어 를 포함하는 켤레류는 입니다.
관찰
원시 단어 의 켤레류는 정확히 개의 서로 다른 단어를 포함합니다.
알파벳 에 대해 어떤 소수인 p의 길이를 갖는 단어의 집합을 생각해봅니다. 가 그 집합의 원시 단어 부분집합이라고 가정합니다. 개의 단어 중에 개만이 원시 단어가 아니며, 즉 문자 에 대해 형태의 단어들입니다. 따라서 다음의 관찰을 유도합니다.
관찰
개의 문자로 된 알파벳에 대해 길이가 소수 인 원시 단어의 수 는 입니다.
에 있는 단어는 원시 단어이기 때문에, 그 단어들 각각의 켤레류는 라는 크기를 갖습니다. 켤레류는 를 크기가 인 집합으로 분할하며, 이것은 가 를 나누며, 개의 분류가 있음을 뜻합니다. 이것으로 정리가 증명됩니다.